要解决的问题
- 如何减少内存碎片
解决方案
通过分析现有的内存分配工具 ptmalloc、tcmalloc,学习其思路。
方案案例
TCMalloc
使用
1.编译时通过-ltcmalloc 链接器接入 tcmalloc
2.运行时指定LD_PRELOAD=""/usr/lib/libtcmalloc.so"
如果不需要使用配套的内存分析器,可以使用libtcmalloc_minimal来减小二进制文件大小。
整体内存申请策略
每个线程有 ThreadCache,然后往上有 CentralCache,再往上有 PageHeap ,最后是 OS:
ThreadCache->CentralCache->PageHeap->OS
如何减少内存碎片
首先 tcmalloc 的碎片率目标是 12.5%,怎么计算呢?对于对齐区间(x, y],内部碎片率是1-(y-x-1)/y,所以保证(1+x)/y <= 0.125即可。
小内存的分配
小内存的定义是小于 256K 字节。如果现在申请 N 字节大小的内存,为了减少碎片的产生,需要进行数据对齐再分配 M,M 会大于等于 N。
数据块的划分粒度会造成内存碎片和性能问题,所以对齐算法很关键。
关键是对 128<=size<=256k 字节范围的对齐处理,其他都是依靠经验写死的判定:
if (size >= 128) {
// Space wasted due to alignment is at most 1/8, i.e., 12.5%.
alignment = (1 << LgFloor(size)) / 8;
}
把 N 向下对齐到2的整数次幂然后除以 8 就可以得出对齐步长,比如 129 的对齐步长是 128/8=16,最终分配的到大小为 128+16=144 字节,点这里看源码。
ThreadCache 维护着一个数组 FreeList,数组的索引是内存块的大小,值对应的一个链表,同一链表内的元素对应的就是未使用的相同大小的内存对象。
要取多大的内存块,根据索引,直接在链表头取即可,内存回收的时候也是同理插入即可。
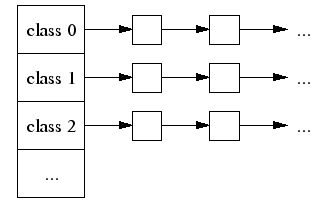
因为是每个线程都有自己的 ThreadCache,所以可以无锁操作 FreeList ,速度很快。如果 FreeList 对应的链表为空,则会向 CentralCache 取,然后插入到对应的链表中。由于 CentralCache 是公用的,所以其分配内存的时候会加内旋锁。
每次向上申请都需要有性能和资源的权衡:申请少了会频繁触发申请操作,申请多了又会浪费,所以对应的有一个慢启动算法来动态调整每次申请的大小。
中等内存的分配
中等内存的定义是256K≤大小≤1MB。它就直接向上对齐到 page 大小了,不再动态计算步长。
中等内存的申请是直接从 PageHeap 取,PageHeap 和 FreeList 的结构类似,也是是一个数组,数组的索引是内存块的大小,值对应的一个链表,同一链表内的元素对应的就是未使用的相同大小的内存对象,只不过对应的内存块更大,是以 page 为单位了,对应的链表也被称为 span。
内存分配方式同 FreeList ,但是它也是公用的,并且内存不够的情况下会向 OS 申请内存,性能损耗更大。
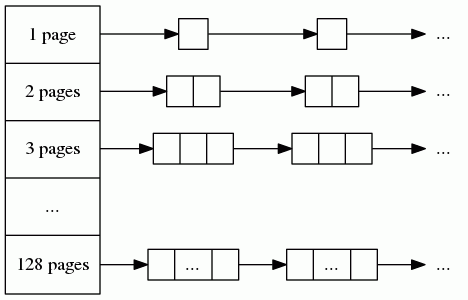
大内存的分配
大内存的定义是1MB或更多。它也是向上对齐到 page 大小,和中等内存分配处理类似。
大内存的分配也是从 PageHeap 取,和中能内存逻辑一样,对齐后得到最终大小:n*page,遍历数组,取对应的 span 值即可。
但是大内存申请有可能 n 大于 128,所以这个时候会从 PageHeap 的一个有序列表中找最合适的 span:有序列表里面就是各种大小的 span,按照容量排序,使用红黑树结构方便查找最合适的的结果 m。当 m-n 依然大于 128 的时候会将剩余的容量再次放回有序列表中;当 m-n 小于等于 128 的时候,会插入对应数组的 span 中;如果没有找到期望的 m 则会向 OS 申请内存。
有序列表中的 span 可能是从 OS 中多次申请过来的,也可能是内存回收后的。
内存的回收
小内存的回收,存在于 ThreadCache 中,小于 2M 的时候都是自己管理,回收的内存超过 2M 后,就会返还给 CentralCache。
大内存下的回收则是以 page 为基本单位来操作的,CentralCache 返还也是以 page 为单位,所以关键在于 page 的回收处理。
因为最后申请的时候都是拆分 PageHeap 中的 span,大拆小容易,反之则不行,所以尽量在回收的时候尽量多合并整合,减少内存碎片。
下图是在 PageHeap 中 page 和 span 的映射图,a span 大小为 2,而 b span 大小为 1。
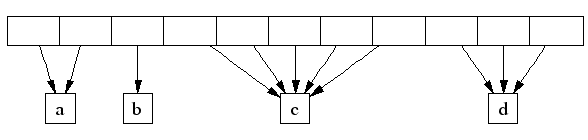
这里就需要通过 PageMap 来记录 page 到 span 的映射关系,PageMap 用 RadixTree 来记录这个映射关系。
从 PageMap 通过 page 找到对应的 span,然后通过 span 找到 page 的范围 [m,n],检查 m-1 和 n+1 所在的 span 是否也是未使用的,如果是的话,则合并成一个大的 span 插到 PageHeap 对应的数组中。
通过伙伴算法进行回收得到的应该是一个大小为 3 的 span。
JeMalloc
使用
1.编译时通过-ljemalloc 链接器接入 jemalloc
2.运行时指定LD_PRELOAD="/usr/lib/libjemalloc.so"
整体内存申请策略
每个线程有 tcache,然后往上有 extent,再往上有 arena ,最后是 OS。
如何减少内存碎片
jemalloc 对小内存的划分方式和 tcmalloc 类似,并不都是2的次幂,大内存的划分方式则是从 4*page 开始。
对于小内存的分配,jemalloc 引入一个更细粒度的结构 slab。每种 slab 对应的就是不同大小的小内存块。小内存块也是有缓存的,叫做 cache_bin,所以小内存分配的流程是:
cache_bin->tcache->extent->arena->os
对于大内存的分配则不走 tcache ,直接从 extent 取。
内存整体上的分配方式和 jemalloc 类似,都是不够了就往上级取,但是区别在于 extent 分成了 3 级:extents_dirty 、extents_muzzy和extents_retained:
extents_dirty可能是回收来的也可能是分配后剩余的部分。extents_muzzy则是extents_dirty回收后的。extents_retained则是extents_muzzy回收后的。
jemalloc 在分配内存的时候优先从 extents_dirty里面分配,不够了会优先对它进行回收然后再分配。分配的方式通过 Pairing Heap(配对堆)而不再是红黑树来找到一个最合适的大小 m,可能 m 依然大于所需的 n,为了减少内存碎片,会将多余的部分再放回 extents_dirty,放回的过程中依然会使用伙伴算法进行合并操作进一步减少内存碎片。
从extents_muzzy和extents_retained上分配内存则使用的另外的策略来逐级减少内存碎片问题:使用满足大小且排在最前面的内存块,即一直使用最旧的内存块。后续减少内存碎片的手段与 extents_dirty里面的操作一样。
所以 jemalloc 先是将依据 CPU 核心数将内存分成不同数量且各自独立的 arena。然后内部对内存做了类似生命周期的分级策略,对分配最频繁的一级extents_dirty通过 Pairing Heap 来选择最合适的内存块,并且进行伙伴算法来减少内存碎片,后面 2 级则遵循“最旧优先”的策略来分配内存,同时使用伙伴算法来减少内存碎片。
性能上则是通过独立的 arena 来减少线程同步的开销,通过 extents 以及 tcache、bin 等细分结构来降低锁的粒度。但是因为层级划分更细,需要更多的空间来存储相应的信息,同时由于 arena 互相独立,arena 的内存分配上可能不连续,导致内存回收效率低下。